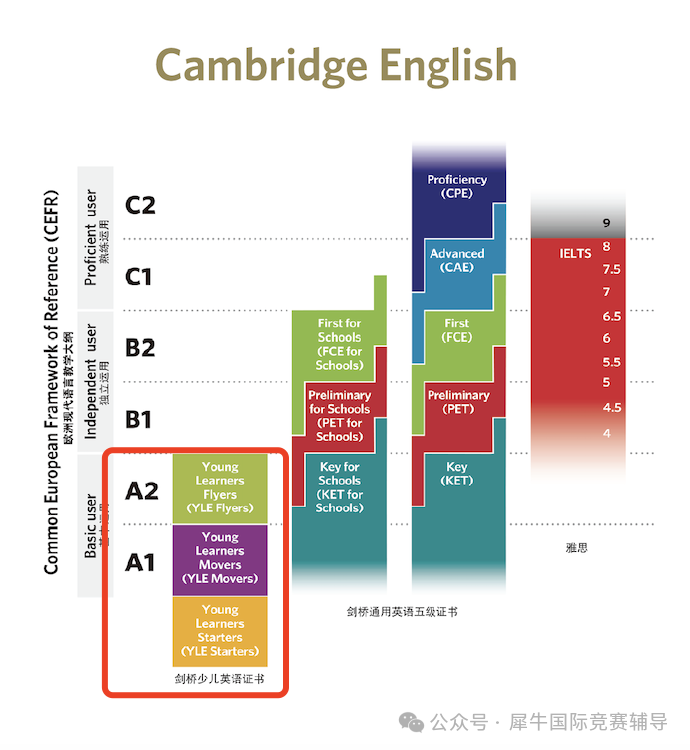
A Primer in BERTology: What we know about how BERT works, 2022, https://arxiv.org/abs/2002.12327
基于Transformer的NLP模型现在广泛应用,但我们对它们的内部工作原理仍然知之甚少。
本篇论文的内容包括:
- BERT模型的原理和预训练
- BERT模型适用场景和
- BERT模型分支、压缩和改进方向
BERT模型介绍
BERT是一堆Transformer编码器组成。对于序列中的每个输入,每个头计算键、值和查询向量,用于创建加权表示。同一层中所有头的输出通过一个全连接层运行合并。
原始BERT的训练流程包括两个阶段:预训练和微调。预训练使用两个自监督任务:masked language modeling(MLM,随机屏蔽输入的预测)和next sentence prediction(NSP,预测两个输入句子是否彼此相邻)。在对下游任务进行微调时,通常会在最终编码器层之上添加一个或多个全连接层。
BERT首先将给输入通过wordpieces进行处理,然后将三个嵌入层(标记、位置和段)获得固定长度的向量。特殊标记[CLS]用于预测分类,[SEP]分隔输入输入段。原始BERT有两个版本:base 和 large,分别在层数、隐藏层大小和注意力头数上存在差异。
BERT「掌握」的知识
语法知识
研究表明BERT表示是分层的而不是线性的,除了词序信息之外还有类似于句法树结构的知识。
句法结构似乎并没有直接编码在自注意力权重中,但它们可以从token的表示恢复出来。

BERT对格式错误的输入不敏感,即使打乱词序、截断句子、删除主语和宾语,它的预测也没有改变。
语义知识
BERT能够做出正确的MLM预测,则不是简单的填写单词。BERT可以捕获实体、关系和角色等信息。
BERT很难表示数值,并且很难从训练数据中泛化。其中的一个原因,可能是wordpieces将数字进行了拆分。
通用知识
BERT通过MLM可以进行预测,并比常规的方法行囊够更好。但BERT不能直接用于逻辑推理。
BERT模型训练
Pre-training BERT
原始的 BERT是在两个任务进行预训练:下一句预测 (NSP) 和掩码语言模型 (MLM)。有多项研究对预训练任务进行了改进:
- How to mask
- with corruption rate and corrupted span length
- diverse masks for training examples within an epoch
- replace the MASK token with [UNK] token
- What to mask
- applied to full words instead of word-pieces
- mask spans rather than single tokens
- mask phrases and named entities
- Where to mask
- arbitrary text streams instead of sentence pairs
- MLM with partially autoregressive LM
- Alternatives to masking
- deletion, infilling, sentence permutation and document rotation
- predict whether a token is capitalized and whether it occurs in other segments of the same documen
- train on different permutations of word order in the input sequence, maximizing the probability of the original word order
- detects tokens that were replaced by a generator network rather than masked
- NSP alternatives
- remove NSP does not hurt or slightly improves performance
- replace NSP with the task of predicting both the next and the previous sentences
- replace the negative NSP examples by swapped sentences from positive examples
- sentence reordering and sentence distance prediction
Fine-tuning BERT
预训练+微调是BERT的使用流程。前者是为了提供任务无关的知识,而后者教导模型学习对当前任务有用的表征。
有多项研究对微调进行了改进:
- Taking more layers into account
- Two-stage fine-tuning
- Adversarial token perturbations
- Adversarial regularization
- Mixout regularization
BERT模型压缩
通过模型蒸馏、量化和剪枝,BERT模型可以在损失较少精度的同时获得成倍的加速。
具体的方法可以参考下表:

【竞赛报名/项目咨询请加微信:mollywei007】